“中國歷代人物傳記資料庫”的版本间的差异
Tsui lincoln(讨论 | 贡献) (→可視化) |
|||
| 第24行: | 第24行: | ||
==CBDB的內容== | ==CBDB的內容== | ||
| − | [[File:CBDB 2017 Data by Period.png| | + | [[File:CBDB 2017 Data by Period.png|300px|thumb|right]] |
上圖中的人物展示了2018年1月CBDB中各個朝代人物的數量。朝代之間數據量的差異和所使用的資料有巨大的關係。例如,明代數據如此之多,是由於CBDB幾乎完整地挖掘了明代進士的傳記資料。在這些明代進士的資料中,不僅包括這些進士的父(F)、母(M)、祖父(FF)和曾祖父(FFF),也包括了他們的兄(B+)、弟(B-)。 | 上圖中的人物展示了2018年1月CBDB中各個朝代人物的數量。朝代之間數據量的差異和所使用的資料有巨大的關係。例如,明代數據如此之多,是由於CBDB幾乎完整地挖掘了明代進士的傳記資料。在這些明代進士的資料中,不僅包括這些進士的父(F)、母(M)、祖父(FF)和曾祖父(FFF),也包括了他們的兄(B+)、弟(B-)。 | ||
CBDB制定了一條規則,此規則是按照人的死亡日期來把他歸入某一朝代,雖然他可能在多於一個朝代擔任過官職。然而,許多人物的記錄中並沒有確切的死亡年齡。為了解決這個問題,我們設計了「指數年(index year)」規則。指數年是一個擬定的年份,它代表了我們對這個人物60歲時年份(實歲59,虛歲60)的最合理推測。如果此人在60歲之前死亡,那麼指數年就以他的死亡年份為準。指數年是通過一批基於CBDB數據所設計的規則計算出來的。例如,CBDB中人物平均考中進士的年紀是30歲、妻子比丈夫小2歲半、第一個活下來的兒子通常在父親30歲時候出生等等,這些都是基於歷史數據而得出的觀察。因此,只要確定家族內一人的指數年,就可以推斷得整個家族所有人的指數年,以此釐定人物最可能的年代。總的來說,這個規則運行得非常理想。不過,如果要計算的人物跨域了超過兩個世代,指數年的精確性自然大大下降。由於歷史記錄有大量遺漏,學者往往不知道某個人物的確切年代,運用指數年對CBDB中以時間參數來進行查詢非常有必要,也很有幫助。 | CBDB制定了一條規則,此規則是按照人的死亡日期來把他歸入某一朝代,雖然他可能在多於一個朝代擔任過官職。然而,許多人物的記錄中並沒有確切的死亡年齡。為了解決這個問題,我們設計了「指數年(index year)」規則。指數年是一個擬定的年份,它代表了我們對這個人物60歲時年份(實歲59,虛歲60)的最合理推測。如果此人在60歲之前死亡,那麼指數年就以他的死亡年份為準。指數年是通過一批基於CBDB數據所設計的規則計算出來的。例如,CBDB中人物平均考中進士的年紀是30歲、妻子比丈夫小2歲半、第一個活下來的兒子通常在父親30歲時候出生等等,這些都是基於歷史數據而得出的觀察。因此,只要確定家族內一人的指數年,就可以推斷得整個家族所有人的指數年,以此釐定人物最可能的年代。總的來說,這個規則運行得非常理想。不過,如果要計算的人物跨域了超過兩個世代,指數年的精確性自然大大下降。由於歷史記錄有大量遺漏,學者往往不知道某個人物的確切年代,運用指數年對CBDB中以時間參數來進行查詢非常有必要,也很有幫助。 | ||
| − | [[File:CBDB 2017 Data by table.png| | + | [[File:CBDB 2017 Data by table.png|300px|thumb|left]] |
CBDB搜集歷史人物的多方面數據,涵蓋面非常廣泛。各種種數據數量的分佈,請見上圖。每種數據都對應著CBDB中一個代碼表。在主要的傳記信息表中,每一個人物都有一個獨一無二的ID。這個ID會在很多個數據表中被系統使用。CBDB中對歷史上人的235種社會關係做了編碼。它們進一步被分成若干個類別,最主要的有著作關係、政治關係和學術關係。而CBDB中有20種傳記地址代碼,包括出生地、死亡地和埋葬地、籍貫、祖籍、清代八旗、前往地等。7種別名代碼包括:字、室名別號、謚號、法號、行第、小名等。每種可能的親屬關係同樣有被系統編碼。不過這些關係被簡化成了最短的關係,如父(F)、子(S)、夫(H)妻(W)。用戶可以在需要時利用電腦計算,生成親屬關係的樹狀圖。入仕代碼對多種不同入仕模式做了編碼,包括各種考試、推薦、恩蔭、捐納等等。官職代碼包括朝代中所有的官名、品級以及任官地址。官職信息可以通過官名樹來查詢,讓用戶可以在官僚結構樹中查詢某一部分的所有官職。著作包括歷史人物存佚的各種著作。如果有相關信息,其著作的目錄學分類也會被CBDB記錄下來。 | CBDB搜集歷史人物的多方面數據,涵蓋面非常廣泛。各種種數據數量的分佈,請見上圖。每種數據都對應著CBDB中一個代碼表。在主要的傳記信息表中,每一個人物都有一個獨一無二的ID。這個ID會在很多個數據表中被系統使用。CBDB中對歷史上人的235種社會關係做了編碼。它們進一步被分成若干個類別,最主要的有著作關係、政治關係和學術關係。而CBDB中有20種傳記地址代碼,包括出生地、死亡地和埋葬地、籍貫、祖籍、清代八旗、前往地等。7種別名代碼包括:字、室名別號、謚號、法號、行第、小名等。每種可能的親屬關係同樣有被系統編碼。不過這些關係被簡化成了最短的關係,如父(F)、子(S)、夫(H)妻(W)。用戶可以在需要時利用電腦計算,生成親屬關係的樹狀圖。入仕代碼對多種不同入仕模式做了編碼,包括各種考試、推薦、恩蔭、捐納等等。官職代碼包括朝代中所有的官名、品級以及任官地址。官職信息可以通過官名樹來查詢,讓用戶可以在官僚結構樹中查詢某一部分的所有官職。著作包括歷史人物存佚的各種著作。如果有相關信息,其著作的目錄學分類也會被CBDB記錄下來。 | ||
| − | + | <br clear=all> | |
==可視化== | ==可視化== | ||
| − | CBDB數據可供學者進行群體傳記學研究。<ref>{{cite journal|last1=Gerritsen|first1=Anne|title=Prosopography and its Potential for Middle Period Research (Workshop on the Prosopography of Middle Period China: Using the China Biographical Database)|journal=[[Journal of Song-Yuan Studies]]|date=2008|volume=38|pages=161–201}}</ref> 通過查詢和導入,可以利用統計分析工具和可視化工具對CBDB數據進行數據分析和可視化。 | + | CBDB數據可供學者進行群體傳記學研究。<ref>{{cite journal|last1=Gerritsen|first1=Anne|title=Prosopography and its Potential for Middle Period Research (Workshop on the Prosopography of Middle Period China: Using the China Biographical Database)|journal=[[Journal of Song-Yuan Studies]]|date=2008|volume=38|pages=161–201}}</ref> 通過查詢和導入,可以利用統計分析工具和可視化工具對CBDB數據進行數據分析和可視化。 |
| − | |||
| − | |||
上圖是CBDB中男性和女性壽命中位數的對比。當我們不區分性別的時候,數據的差異性被掩蓋過去,沒有顯現出來。壽命上差異是由育齡女性死亡率較高導致的。CBDB 數據中大約10%是女性。CBDB查詢的結果還可以被輕鬆地導出,進行另外兩種可視化——地理信息系統和社會網絡關係分析。在下圖中我們用兩種方法對同一批數據進行可視化,以揭示不同方法的價值。 | 上圖是CBDB中男性和女性壽命中位數的對比。當我們不區分性別的時候,數據的差異性被掩蓋過去,沒有顯現出來。壽命上差異是由育齡女性死亡率較高導致的。CBDB 數據中大約10%是女性。CBDB查詢的結果還可以被輕鬆地導出,進行另外兩種可視化——地理信息系統和社會網絡關係分析。在下圖中我們用兩種方法對同一批數據進行可視化,以揭示不同方法的價值。 | ||
| − | |||
在CBDB數據中,宋濂(1310-81)有452條社會關係記錄,我們設定「社會關係」為「文學關係」(包括書信交往、為其寫墓誌)和「學術關係」(包括師生關係)。這些人物被限定為和宋濂之間有直接的社會關係、並至少與另一個人有社會關係。本例子是使用了免費的社會網絡關係分析軟件Pajek。除此之外,CBDB 數據也可以直接導到Gephi 和UCInet這兩個軟件。通過將宋濂社會網絡數據畫到地圖上,我們可以看到他的社會網絡遍佈整個國家,但主要的關係人還是集中在他的籍貫所在。這個可視化使用了Quantum GIS 軟件。Quantum GIS 是可以在PC和MAC上使用的免費軟件。此可視化還用了同樣是免費的「中國歷史地理信息系統第六版(CHGIS v6)」的縣界、河流和數字高程模型(DEM)。CBDB也可以導出供Google Earth 使用的 KML 格式數據。總而言之,CBDB使得簡單和複雜查詢的結果都可以被直接導出到其他軟件,成為可以簡易地使用的數據。研究者可以根據數據,檢視在某一地域的人物中,某一段時間內考取進士者的社會和親屬關係。 | 在CBDB數據中,宋濂(1310-81)有452條社會關係記錄,我們設定「社會關係」為「文學關係」(包括書信交往、為其寫墓誌)和「學術關係」(包括師生關係)。這些人物被限定為和宋濂之間有直接的社會關係、並至少與另一個人有社會關係。本例子是使用了免費的社會網絡關係分析軟件Pajek。除此之外,CBDB 數據也可以直接導到Gephi 和UCInet這兩個軟件。通過將宋濂社會網絡數據畫到地圖上,我們可以看到他的社會網絡遍佈整個國家,但主要的關係人還是集中在他的籍貫所在。這個可視化使用了Quantum GIS 軟件。Quantum GIS 是可以在PC和MAC上使用的免費軟件。此可視化還用了同樣是免費的「中國歷史地理信息系統第六版(CHGIS v6)」的縣界、河流和數字高程模型(DEM)。CBDB也可以導出供Google Earth 使用的 KML 格式數據。總而言之,CBDB使得簡單和複雜查詢的結果都可以被直接導出到其他軟件,成為可以簡易地使用的數據。研究者可以根據數據,檢視在某一地域的人物中,某一段時間內考取進士者的社會和親屬關係。 | ||
| − | + | <gallery mode="traditional" widths=250px heights=200px> | |
| − | + | File:CBDB median Age of Death.png | |
| − | + | File:CBDB median Age of Death-Women.png | |
| + | File:Spatial_Distribution_of_CBDB_Persons.png|CBDB數據中所有人物的地理分佈 | ||
| + | File:Song Lian Network.png|Song Lian's (1310-81) literary and scholarly network | ||
| + | File:Song_Lian_network_mapped.jpg|宋濂的社會網絡關係 圖 | ||
| + | File:Song_Lian_Lit_Sch_network.png | ||
| + | </gallery> | ||
| + | <br clear=all> | ||
==See also== | ==See also== | ||
*[[China Historical Geographic Information System]] (CHGIS) | *[[China Historical Geographic Information System]] (CHGIS) | ||
2018年5月11日 (五) 12:18的版本
中國歷代人物傳記資料(或稱數據)庫係線上的關係型資料庫,其遠程目標在於系統性 地收入中國歷史上所有重要的傳記資料,並將其內容毫無限制地、免費地公諸學術之 用。截至 2017 年 8 月為止,本資料庫共收錄約 417,000 人的傳記資料,這些人物主要 出自七世紀至十九世紀,本資料庫現正致力於增錄更多唐代和明清的人物傳記資料。 本資料庫除可作為人物傳記的一種參考資料外,亦冀可敷統計分析與空間分析之用。
「中國歷代人物傳記資料庫(CBDB)」是關於7世紀到19世紀中國歷史人物的關係型數據庫。截止至2017年8月,CBDB收錄了超過417,000人的傳記信息(包括姓名、生卒年、籍貫、入仕、官職、親屬關係、社會關係等數據)。[1]
項目歷史
CBDB 始於社會史專家郝若貝(1932-1996)的工作。[2]郝若貝首次使用關係型數據庫研究宋代官員的社會和家庭網絡。意識到學界缺乏用於研究中國中古社會史的大型數據集之後,他便踏出了搜集數據的第一步,並通過數據分析,試圖對中國歷史的變遷提出一些有意義的回答。郝若貝透過人名、地名、官僚系統、親屬關係和社會關係等欄目來為數據建立結構。 郝若貝教授去世後,將數據和相關程序遺贈予哈佛燕京學社。當時此數據包含超過25,000個歷史人物,4,500 條書目信息,以及他在歷史地理信息系統方面積累的成果。哈佛燕京學社隨後對此數據失去了興趣,所以自 2005 年開始,哈佛大學的包弼德教授開始著手公開發佈郝若貝的成果,並進行擴展。來自加利福尼亞大學爾灣分校的中國文學教授傅君勱參與負責重新設計程序。在北京大學的鄧小南教授帶領下,北京大學中國古代史研究中心的研究生負責修訂和審核數據庫中的數據。中研院歷史語言研究所柳立言教授向CBDB項目提供了數字化的資料。有賴多個數據庫項目的參與和共同努力,CBDB在數據的時代跨度和數據類型上有了巨大的擴展。CBDB 當前由哈佛大學費正清中國研究中心、中央研究院歷史語言研究所和北大中國古代史研究中心共同擁有。更多關於歷史、資助者、貢獻者的信息,請訪問CBDB項目網站。
資料來源
CBDB 廣泛使用傳記資料文本來獲取人物信息。這些信息包括學者們整理的傳記索引、正史的傳記部分、祭文和墓誌、地方志、個人文集中的部分資料,以及大量官方記錄。 CBDB 是一個長期開放的項目。它當前已經在以下材料搜集傳記數據:《宋人傳記資料索引》、《元人傳記資料索引》、《明人傳記資料索引》、《清代人物生卒年表》、《宋代郡守年表》、宋(1148、1256兩年)明清三代的進士記錄、明代進士考生的親屬資料等。2018年,項目成員正從唐代主要的史料和索引中搜集人物資料。 CBDB同時也和其他數據庫合作、相互交換數據。CBDB的合作者包括:明清婦女著作項目(Ming Qing Women’s Writings)Ming Qing Women’s Writings、人名權威資料查詢人名權威–人物傳記資料查詢,以及京都大學唐代人物知識庫項(Pers-DB Knowledge Base of Tang Persons)等。[3] CBDB項目當前正系統地從地方志和縉紳錄中搜集職官信息。
局限與優勢
CBDB 使用數據挖掘技術,從大量資料中提取數據。在數據挖掘的工作中,由於 CBDB 會首先挑選行文比較系統、格套化的文本,所以數據挖掘是系統地進行的。這意味著,雖然 CBDB的合作者會透過手動錄入某些歷史人物的詳盡個人信息,但CBDB小組本身不會對單個歷史人物進行深入挖掘。數據挖掘的主要目標是從材料中精確提取數據,並對其進行編碼,而不是核查這些源材料的準確性(那往往是文科研究者的工作)。因此,來自不同材料的錯誤與矛盾的資訊有時會依照原狀被保留在數據中。雖然CBDB 區分主要傳記來源和在其他人傳記中提到的此人信息,但CBDB不會只側重某一材料,而認為其可靠性高於所有其他材料。因此,CBDB很好地保存著時代積累下來的史料,而時代越早,史料自然越少。當前CBDB人物數據主要來自七世紀到二十世紀(從唐代到清代)。這些數據是過去歷史記錄的一個「樣本」(而不是全體)。例如,墓誌是記錄親屬關係的重要資料,但是歷史上只有幾萬方墓誌被保存至今。相似地,只有一部分人的文集流傳至今,而這些將被項目組陸續系統地進行挖掘和處理 。由於傳世資料本身的性質,造成CBDB的數據較多是關於歷史上的官員的,而不是其他人物。[4]
雖然用戶可以用CBDB來檢索單個人物的信息,但是CBDB不僅僅是一部人名詞典。它實際上是一份大型,並不斷增長的人物數據集。這些數據包括人物的名字、職業、入仕方式、親屬關係、社會關係以及著作等。我們可以透過查詢這些數據的查詢來分析時空變遷的宏觀趨勢。當我們分析大批量數據的時候,無論是史料的個別舛誤還是編碼工作造成的微量錯誤,對結論都將不會有太大的影響。關係型數據庫向用戶提供了查詢以及設置查詢變量的強大功能,這是人名詞典所無法提供的。
長遠來看,CBDB將全面挖掘現有的中國歷史資料,並將愈來愈準確地反映中國歷史資料中的傳記數據。
CBDB的內容

上圖中的人物展示了2018年1月CBDB中各個朝代人物的數量。朝代之間數據量的差異和所使用的資料有巨大的關係。例如,明代數據如此之多,是由於CBDB幾乎完整地挖掘了明代進士的傳記資料。在這些明代進士的資料中,不僅包括這些進士的父(F)、母(M)、祖父(FF)和曾祖父(FFF),也包括了他們的兄(B+)、弟(B-)。
CBDB制定了一條規則,此規則是按照人的死亡日期來把他歸入某一朝代,雖然他可能在多於一個朝代擔任過官職。然而,許多人物的記錄中並沒有確切的死亡年齡。為了解決這個問題,我們設計了「指數年(index year)」規則。指數年是一個擬定的年份,它代表了我們對這個人物60歲時年份(實歲59,虛歲60)的最合理推測。如果此人在60歲之前死亡,那麼指數年就以他的死亡年份為準。指數年是通過一批基於CBDB數據所設計的規則計算出來的。例如,CBDB中人物平均考中進士的年紀是30歲、妻子比丈夫小2歲半、第一個活下來的兒子通常在父親30歲時候出生等等,這些都是基於歷史數據而得出的觀察。因此,只要確定家族內一人的指數年,就可以推斷得整個家族所有人的指數年,以此釐定人物最可能的年代。總的來說,這個規則運行得非常理想。不過,如果要計算的人物跨域了超過兩個世代,指數年的精確性自然大大下降。由於歷史記錄有大量遺漏,學者往往不知道某個人物的確切年代,運用指數年對CBDB中以時間參數來進行查詢非常有必要,也很有幫助。

CBDB搜集歷史人物的多方面數據,涵蓋面非常廣泛。各種種數據數量的分佈,請見上圖。每種數據都對應著CBDB中一個代碼表。在主要的傳記信息表中,每一個人物都有一個獨一無二的ID。這個ID會在很多個數據表中被系統使用。CBDB中對歷史上人的235種社會關係做了編碼。它們進一步被分成若干個類別,最主要的有著作關係、政治關係和學術關係。而CBDB中有20種傳記地址代碼,包括出生地、死亡地和埋葬地、籍貫、祖籍、清代八旗、前往地等。7種別名代碼包括:字、室名別號、謚號、法號、行第、小名等。每種可能的親屬關係同樣有被系統編碼。不過這些關係被簡化成了最短的關係,如父(F)、子(S)、夫(H)妻(W)。用戶可以在需要時利用電腦計算,生成親屬關係的樹狀圖。入仕代碼對多種不同入仕模式做了編碼,包括各種考試、推薦、恩蔭、捐納等等。官職代碼包括朝代中所有的官名、品級以及任官地址。官職信息可以通過官名樹來查詢,讓用戶可以在官僚結構樹中查詢某一部分的所有官職。著作包括歷史人物存佚的各種著作。如果有相關信息,其著作的目錄學分類也會被CBDB記錄下來。
可視化
CBDB數據可供學者進行群體傳記學研究。[5] 通過查詢和導入,可以利用統計分析工具和可視化工具對CBDB數據進行數據分析和可視化。
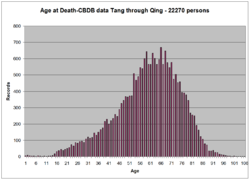
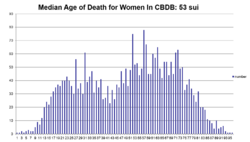
上圖是CBDB中男性和女性壽命中位數的對比。當我們不區分性別的時候,數據的差異性被掩蓋過去,沒有顯現出來。壽命上差異是由育齡女性死亡率較高導致的。CBDB 數據中大約10%是女性。CBDB查詢的結果還可以被輕鬆地導出,進行另外兩種可視化——地理信息系統和社會網絡關係分析。在下圖中我們用兩種方法對同一批數據進行可視化,以揭示不同方法的價值。
在CBDB數據中,宋濂(1310-81)有452條社會關係記錄,我們設定「社會關係」為「文學關係」(包括書信交往、為其寫墓誌)和「學術關係」(包括師生關係)。這些人物被限定為和宋濂之間有直接的社會關係、並至少與另一個人有社會關係。本例子是使用了免費的社會網絡關係分析軟件Pajek。除此之外,CBDB 數據也可以直接導到Gephi 和UCInet這兩個軟件。通過將宋濂社會網絡數據畫到地圖上,我們可以看到他的社會網絡遍佈整個國家,但主要的關係人還是集中在他的籍貫所在。這個可視化使用了Quantum GIS 軟件。Quantum GIS 是可以在PC和MAC上使用的免費軟件。此可視化還用了同樣是免費的「中國歷史地理信息系統第六版(CHGIS v6)」的縣界、河流和數字高程模型(DEM)。CBDB也可以導出供Google Earth 使用的 KML 格式數據。總而言之,CBDB使得簡單和複雜查詢的結果都可以被直接導出到其他軟件,成為可以簡易地使用的數據。研究者可以根據數據,檢視在某一地域的人物中,某一段時間內考取進士者的社會和親屬關係。
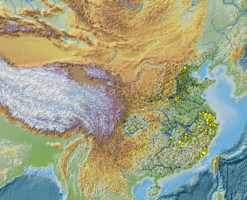
CBDB數據中所有人物的地理分佈

Song Lian's (1310-81) literary and scholarly network
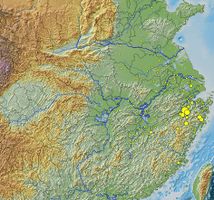
宋濂的社會網絡關係圖







See also
References
- ↑ China Biographical Database Project (CBDB). Projects.iq.harvard.edu. 2016-11-07 [2016-12-11].
- ↑ Smith, Paul J. "Obituary: Robert M. Hartwell (1932-1996)". Journal of Song Yuan Studies 27. 1997.
- ↑ Reviews of Internet resources for Asian Studies. Resource: China Biographical Database Project (CBDB) [New Release] (Jan 2011, Vol. 18, No. 1, 320). The Asian Studies WWW Monitor.
- ↑ New Approaches in Chinese Digital Humanities - CBDB and Digging into Data Workshop. Peking University. Office of International Relations. 2016-01-11.
- ↑ Gerritsen, Anne. Prosopography and its Potential for Middle Period Research (Workshop on the Prosopography of Middle Period China: Using the China Biographical Database). Journal of Song-Yuan Studies. 2008, 38: 161–201.
Further reading
- Peter K. Bol, Chao-Lin Liu, and Hongsu Wang, Mining and Discovering Biographical Information in Difangzhi with a Language-Model-based Approach[1]
- Peter K. Bol, "The Late Robert M. Hartwell 'Chinese Historical Studies, Ltd.' Software Project," 1999[2]
- Anne Gerritsen, "Using the CBDB for the study of women and gender? Some of the pitfalls" December 2007[3]
- Fuller, Michael A. "The China Biographical Database User's Guide," February 28, 2015[4]
- "Online Guide to Querying and Reporting System," Academia Sinica[5]ZH:中國歷代人物傳記資料庫
外部链接
- 中國歷代人物傳記資料庫
- ↑ Mining and Discovering Biographical Information in Difangzhi with a Language-Model-based Approach (PDF). Arvix.org. [2016-12-11].
- ↑ Peter Bol. The Late Robert M. Hartwell "Chinese Historical Studies, Ltd." Software Project (PDF). Pnclink.org. [2016-12-11].
- ↑ Anne Gerritsen. Using the CBDB for the study of women and gender? Some of the pitfalls (PDF). Humanities.uci.edu. [2016-12-11].
- ↑ Michael A. Fuller. The China Biographical Database : User's Guide (PDF). Projects.iq.harvard.edu. February 28, 2015 [2016-12-11].
- ↑ CBDB Querying and Reporting System - Online Help. Db1.ihp.sinica.edu.tw. [2016-12-11].