中国历代人物传记资料库
中国历代人物传记资料(或称数据)库系线上的关系型资料库,其远程目标在于系统性 地收入中国历史上所有重要的传记资料,并将其内容毫无限制地、免费地公诸学术之 用。截至 2017 年 8 月为止,本资料库共收录约 417,000 人的传记资料,这些人物主要 出自七世纪至十九世纪,本资料库现正致力于增录更多唐代和明清的人物传记资料。 本资料库除可作为人物传记的一种参考资料外,亦冀可敷统计分析与空间分析之用。
“中国历代人物传记资料库(CBDB)”是关于7世纪到19世纪中国历史人物的关系型数据库。截止至2017年8月,CBDB收录了超过417,000人的传记信息(包括姓名、生卒年、籍贯、入仕、官职、亲属关系、社会关系等数据)。[1]
项目历史
CBDB 始于社会史专家郝若贝(1932-1996)的工作。[2]郝若贝首次使用关系型数据库研究宋代官员的社会和家庭网络。意识到学界缺乏用于研究中国中古社会史的大型数据集之后,他便踏出了搜集数据的第一步,并通过数据分析,试图对中国历史的变迁提出一些有意义的回答。郝若贝透过人名、地名、官僚系统、亲属关系和社会关系等栏目来为数据建立结构。 郝若贝教授去世后,将数据和相关程序遗赠予哈佛燕京学社。当时此数据包含超过25,000个历史人物,4,500 条书目信息,以及他在历史地理信息系统方面积累的成果。哈佛燕京学社随后对此数据失去了兴趣,所以自 2005 年开始,哈佛大学的包弼德教授开始著手公开发布郝若贝的成果,并进行扩展。来自加利福尼亚大学尔湾分校的中国文学教授傅君劢参与负责重新设计程序。在北京大学的邓小南教授带领下,北京大学中国古代史研究中心的研究生负责修订和审核数据库中的数据。中研院历史语言研究所柳立言教授向CBDB项目提供了数字化的资料。有赖多个数据库项目的参与和共同努力,CBDB在数据的时代跨度和数据类型上有了巨大的扩展。CBDB 当前由哈佛大学费正清中国研究中心、中央研究院历史语言研究所和北大中国古代史研究中心共同拥有。更多关于历史、资助者、贡献者的信息,请访问CBDB项目网站。
资料来源
CBDB 广泛使用传记资料文本来获取人物信息。这些信息包括学者们整理的传记索引、正史的传记部分、祭文和墓志、地方志、个人文集中的部分资料,以及大量官方记录。 CBDB 是一个长期开放的项目。它当前已经在以下材料搜集传记数据:《宋人传记资料索引》、《元人传记资料索引》、《明人传记资料索引》、《清代人物生卒年表》、《宋代郡守年表》、宋(1148、1256两年)明清三代的进士记录、明代进士考生的亲属资料等。2018年,项目成员正从唐代主要的史料和索引中搜集人物资料。 CBDB同时也和其他数据库合作、相互交换数据。CBDB的合作者包括:明清妇女著作项目(Ming Qing Women’s Writings)Ming Qing Women’s Writings、人名权威资料查询人名权威–人物传记资料查询,以及京都大学唐代人物知识库项(Pers-DB Knowledge Base of Tang Persons)等。[3] CBDB项目当前正系统地从地方志和缙绅录中搜集职官信息。
局限与优势
CBDB 使用数据挖掘技术,从大量资料中提取数据。在数据挖掘的工作中,由于 CBDB 会首先挑选行文比较系统、格套化的文本,所以数据挖掘是系统地进行的。这意味著,虽然 CBDB的合作者会透过手动录入某些历史人物的详尽个人信息,但CBDB小组本身不会对单个历史人物进行深入挖掘。数据挖掘的主要目标是从材料中精确提取数据,并对其进行编码,而不是核查这些源材料的准确性(那往往是文科研究者的工作)。因此,来自不同材料的错误与矛盾的资讯有时会依照原状被保留在数据中。虽然CBDB 区分主要传记来源和在其他人传记中提到的此人信息,但CBDB不会只侧重某一材料,而认为其可靠性高于所有其他材料。因此,CBDB很好地保存著时代积累下来的史料,而时代越早,史料自然越少。当前CBDB人物数据主要来自七世纪到二十世纪(从唐代到清代)。这些数据是过去历史记录的一个“样本”(而不是全体)。例如,墓志是记录亲属关系的重要资料,但是历史上只有几万方墓志被保存至今。相似地,只有一部分人的文集流传至今,而这些将被项目组陆续系统地进行挖掘和处理 。由于传世资料本身的性质,造成CBDB的数据较多是关于历史上的官员的,而不是其他人物。[4]
虽然用户可以用CBDB来检索单个人物的信息,但是CBDB不仅仅是一部人名词典。它实际上是一份大型,并不断增长的人物数据集。这些数据包括人物的名字、职业、入仕方式、亲属关系、社会关系以及著作等。我们可以透过查询这些数据的查询来分析时空变迁的宏观趋势。当我们分析大批量数据的时候,无论是史料的个别舛误还是编码工作造成的微量错误,对结论都将不会有太大的影响。关系型数据库向用户提供了查询以及设置查询变量的强大功能,这是人名词典所无法提供的。
长远来看,CBDB将全面挖掘现有的中国历史资料,并将愈来愈准确地反映中国历史资料中的传记数据。
CBDB的内容

上图中的人物展示了2018年1月CBDB中各个朝代人物的数量。朝代之间数据量的差异和所使用的资料有巨大的关系。例如,明代数据如此之多,是由于CBDB几乎完整地挖掘了明代进士的传记资料。在这些明代进士的资料中,不仅包括这些进士的父(F)、母(M)、祖父(FF)和曾祖父(FFF),也包括了他们的兄(B+)、弟(B-)。
CBDB制定了一条规则,此规则是按照人的死亡日期来把他归入某一朝代,虽然他可能在多于一个朝代担任过官职。然而,许多人物的记录中并没有确切的死亡年龄。为了解决这个问题,我们设计了“指数年(index year)”规则。指数年是一个拟定的年份,它代表了我们对这个人物60岁时年份(实岁59,虚岁60)的最合理推测。如果此人在60岁之前死亡,那么指数年就以他的死亡年份为准。指数年是通过一批基于CBDB数据所设计的规则计算出来的。例如,CBDB中人物平均考中进士的年纪是30岁、妻子比丈夫小2岁半、第一个活下来的儿子通常在父亲30岁时候出生等等,这些都是基于历史数据而得出的观察。因此,只要确定家族内一人的指数年,就可以推断得整个家族所有人的指数年,以此釐定人物最可能的年代。总的来说,这个规则运行得非常理想。不过,如果要计算的人物跨域了超过两个世代,指数年的精确性自然大大下降。由于历史记录有大量遗漏,学者往往不知道某个人物的确切年代,运用指数年对CBDB中以时间参数来进行查询非常有必要,也很有帮助。

CBDB搜集历史人物的多方面数据,涵盖面非常广泛。各种种数据数量的分布,请见上图。每种数据都对应著CBDB中一个代码表。在主要的传记信息表中,每一个人物都有一个独一无二的ID。这个ID会在很多个数据表中被系统使用。CBDB中对历史上人的235种社会关系做了编码。它们进一步被分成若干个类别,最主要的有著作关系、政治关系和学术关系。而CBDB中有20种传记地址代码,包括出生地、死亡地和埋葬地、籍贯、祖籍、清代八旗、前往地等。7种别名代码包括:字、室名别号、谥号、法号、行第、小名等。每种可能的亲属关系同样有被系统编码。不过这些关系被简化成了最短的关系,如父(F)、子(S)、夫(H)妻(W)。用户可以在需要时利用电脑计算,生成亲属关系的树状图。入仕代码对多种不同入仕模式做了编码,包括各种考试、推荐、恩荫、捐纳等等。官职代码包括朝代中所有的官名、品级以及任官地址。官职信息可以通过官名树来查询,让用户可以在官僚结构树中查询某一部分的所有官职。著作包括历史人物存佚的各种著作。如果有相关信息,其著作的目录学分类也会被CBDB记录下来。
可视化
CBDB数据可供学者进行群体传记学研究。[5] 通过查询和导入,可以利用统计分析工具和可视化工具对CBDB数据进行数据分析和可视化。
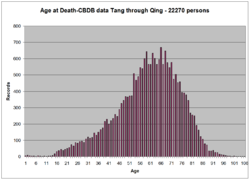
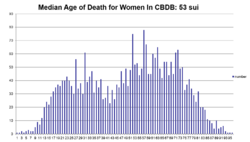
上图是CBDB中男性和女性寿命中位数的对比。当我们不区分性别的时候,数据的差异性被掩盖过去,没有显现出来。寿命上差异是由育龄女性死亡率较高导致的。CBDB 数据中大约10%是女性。CBDB查询的结果还可以被轻松地导出,进行另外两种可视化——地理信息系统和社会网络关系分析。在下图中我们用两种方法对同一批数据进行可视化,以揭示不同方法的价值。
在CBDB数据中,宋濂(1310-81)有452条社会关系记录,我们设定“社会关系”为“文学关系”(包括书信交往、为其写墓志)和“学术关系”(包括师生关系)。这些人物被限定为和宋濂之间有直接的社会关系、并至少与另一个人有社会关系。本例子是使用了免费的社会网络关系分析软件Pajek。除此之外,CBDB 数据也可以直接导到Gephi 和UCInet这两个软件。通过将宋濂社会网络数据画到地图上,我们可以看到他的社会网络遍布整个国家,但主要的关系人还是集中在他的籍贯所在。这个可视化使用了Quantum GIS 软件。Quantum GIS 是可以在PC和MAC上使用的免费软件。此可视化还用了同样是免费的“中国历史地理信息系统第六版(CHGIS v6)”的县界、河流和数字高程模型(DEM)。CBDB也可以导出供Google Earth 使用的 KML 格式数据。总而言之,CBDB使得简单和复杂查询的结果都可以被直接导出到其他软件,成为可以简易地使用的数据。研究者可以根据数据,检视在某一地域的人物中,某一段时间内考取进士者的社会和亲属关系。
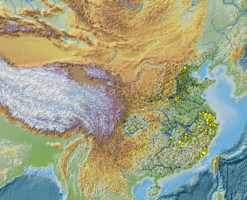
CBDB数据中所有人物的地理分布

Song Lian's (1310-81) literary and scholarly network
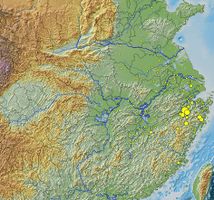
宋濂的社会网络关系图







See also
References
- ↑ China Biographical Database Project (CBDB). Projects.iq.harvard.edu. 2016-11-07 [2016-12-11].
- ↑ Smith, Paul J. "Obituary: Robert M. Hartwell (1932-1996)". Journal of Song Yuan Studies 27. 1997.
- ↑ Reviews of Internet resources for Asian Studies. Resource: China Biographical Database Project (CBDB) [New Release] (Jan 2011, Vol. 18, No. 1, 320). The Asian Studies WWW Monitor.
- ↑ New Approaches in Chinese Digital Humanities - CBDB and Digging into Data Workshop. Peking University. Office of International Relations. 2016-01-11.
- ↑ Gerritsen, Anne. Prosopography and its Potential for Middle Period Research (Workshop on the Prosopography of Middle Period China: Using the China Biographical Database). Journal of Song-Yuan Studies. 2008, 38: 161–201.
Further reading
- Peter K. Bol, Chao-Lin Liu, and Hongsu Wang, Mining and Discovering Biographical Information in Difangzhi with a Language-Model-based Approach[1]
- Peter K. Bol, "The Late Robert M. Hartwell 'Chinese Historical Studies, Ltd.' Software Project," 1999[2]
- Anne Gerritsen, "Using the CBDB for the study of women and gender? Some of the pitfalls" December 2007[3]
- Fuller, Michael A. "The China Biographical Database User's Guide," February 28, 2015[4]
- "Online Guide to Querying and Reporting System," Academia Sinica[5]ZH:中国历代人物传记资料库
外部链接
- 中国历代人物传记资料库
- ↑ Mining and Discovering Biographical Information in Difangzhi with a Language-Model-based Approach (PDF). Arvix.org. [2016-12-11].
- ↑ Peter Bol. The Late Robert M. Hartwell "Chinese Historical Studies, Ltd." Software Project (PDF). Pnclink.org. [2016-12-11].
- ↑ Anne Gerritsen. Using the CBDB for the study of women and gender? Some of the pitfalls (PDF). Humanities.uci.edu. [2016-12-11].
- ↑ Michael A. Fuller. The China Biographical Database : User's Guide (PDF). Projects.iq.harvard.edu. February 28, 2015 [2016-12-11].
- ↑ CBDB Querying and Reporting System - Online Help. Db1.ihp.sinica.edu.tw. [2016-12-11].